

AMD, büyük dil modelleri için çıkarım performansını artırmayı hedefleyen yeni vLLM-ATOM eklentisini duyurdu. Wccftech’in aktardığına göre çözüm, özellikle AMD Instinct MI350 ve MI400 serisi hızlandırıcılar için tasarlandı ve hem bağımsız bir inference sunucusu olarak hem de doğrudan vLLM arka ucu şeklinde çalışabiliyor.
Şirketin verdiği mesaja göre vLLM-ATOM’un en önemli noktası, mevcut vLLM komutları, API’leri ve uçtan uca iş akışlarıyla tam uyum sunması. Yani kullanıcıların yeni bir araç seti öğrenmesi ya da karmaşık yapılandırmalar yapması gerekmiyor; eklenti arka planda çalışırken AMD’nin kendi model ve çekirdek optimizasyonlarından yararlanılabiliyor. Bu yaklaşım, vLLM çekirdek kod tabanında değişiklik yapmadan performans kazanımı sağlamayı amaçlıyor.
AMD ayrıca bu eklentiyle kendi donanım yeniliklerine daha hızlı erişim vad ediyor. Şirketin örnek olarak verdiği özellikler arasında MI355X GPU’daki FP4 desteği ile MI400 GPU üzerinde rack-scale inference yer alıyor. Çekirdek tarafında ise AITER fused attention ve özel AllReduce gibi optimizasyonlar öne çıkarılıyor. Amaç, bu yeniliklerin ana vLLM kod tabanına eklenmesini beklemeden son kullanıcıya ulaştırılması.
Mimari yapı üç katmandan oluşuyor. Üstteki vLLM katmanı istek zamanlaması, KV cache yönetimi, continuous batching ve OpenAI uyumlu API görevlerini üstleniyor. Orta katmandaki ATOM eklentisi platform kaydı, optimize model uygulamaları, attention arka ucu yönlendirmesi ve çekirdek düzeyi ayarlamaları yapıyor. En alttaki AITER katmanı ise fused MoE, flash attention, quantized GEMM ve RoPE fusion gibi düşük seviyeli GPU çekirdeklerini sağlıyor.
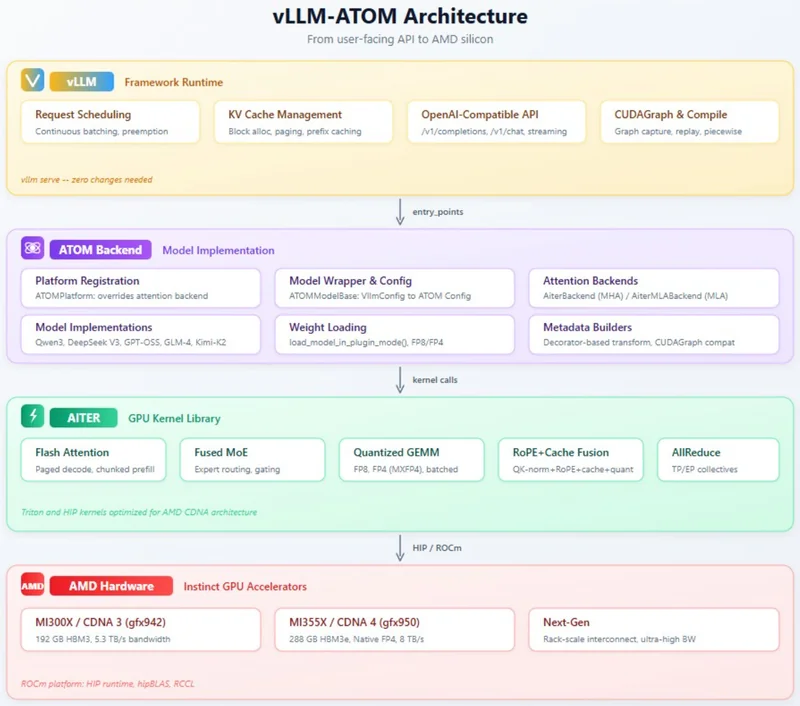
Model desteği tarafında AMD, hem LLM hem de VLM iş yükleri için birleşik bir servis hattı sunduğunu belirtiyor. Desteklenen örnekler arasında Qwen/Qwen3-235B-A22B-Instruct-2507-FP8, deepseek-ai/DeepSeek-R1-0528 (FP8), amd/DeepSeek-R1-0528-MXFP4, openai/gpt-oss-120b, zai-org/GLM-4.7-FP8 ve Qwen/Qwen3-Next-80B-A3B-Instruct-FP8 yer alıyor. Ayrıca Qwen3.5 ve Kimi-K2.5 tabanlı metin ve görsel-dil modelleri de listede bulunuyor.
AMD’nin açıklamasına göre ATOM, yalnızca kısa vadeli bir hızlandırma katmanı değil; aynı zamanda yeni optimizasyonların doğrulandığı bir test alanı olarak konumlandırılıyor. Olgunlaşan çekirdekler ve yazılım iyileştirmeleri zamanla vLLM’nin yerel ROCm arka ucuna aktarılacak. Böylece hem ROCm ekosistemi hem de açık kaynak LLM topluluğu bu çalışmalardan fayda görebilecek.
Özetle vLLM-ATOM, AMD’nin donanıma özgü optimizasyonlarını üretim ortamlarında yaygın kullanılan vLLM çatısı içine daha hızlı taşımayı hedefliyor. Özellikle Instinct MI350 ve MI400 serisini kullanan kurumsal yapılar için, mevcut iş akışlarını bozmadan yeni GPU yeteneklerine erişim sağlama fikri burada asıl odak noktası olarak öne çıkıyor.