

DeepSeek V3-0324 , açık kaynaklı yapay zeka için çığır açıcı bir başarıya imza atarak Yapay Analiz Zeka Endeksi‘nde en yüksek puanı alan akıl yürütmeyen model oldu. Yeni model, Google’ın Gemini 2.0 Pro , Anthropic’in Claude 3.7 Sonnet ve Meta’nın Llama 3.3 70B gibi tescilli emsallerini geride bırakarak kıyaslamada yedi puan yükseldi.
V3-0324, DeepSeek’in kendi R1’i ve OpenAI ve Alibaba’nın teklifleri de dahil olmak üzere akıl yürütme modellerinin gerisinde kalsa da , bu başarı, anında yanıtların kritik olduğu gecikmeye duyarlı uygulamalarda açık kaynaklı çözümlerin giderek daha uygulanabilir olduğunu vurguluyor.
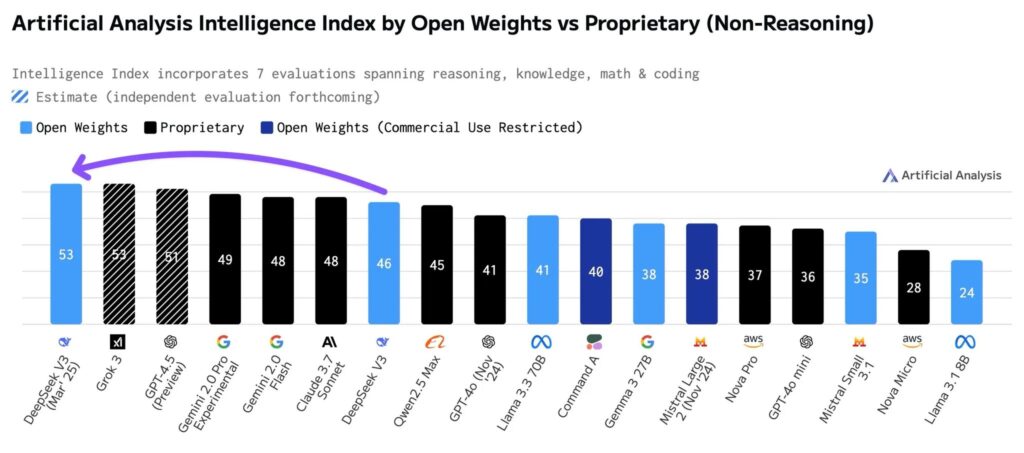
Akıl yürütmeyen modeller – kasıtlı “düşünme” aşamaları olmadan anında yanıtlar üreten – sohbet robotları, müşteri hizmetleri otomasyonu ve canlı çeviri gibi gerçek zamanlı kullanım durumları için olmazsa olmazdır. DeepSeek’in son yinelemesi artık bu uygulamalar için standartları belirliyor ve önde gelen tescilli araçları bile geride bırakıyor.
Yapay Analiz, “Bu, açık ağırlıklar modelinin açık kaynak için bir dönüm noktası olan önde gelen akıl yürütmeyen model olması ilk kez oluyor,” diyor. Modelin performansı, onu tescilli akıl yürütme modellerine yaklaştırıyor, ancak ikincisi karmaşık problem çözme gerektiren görevler için üstün olmaya devam ediyor.
DeepSeek V3-0324, Aralık 2024’teki selefinden gelen özelliklerin çoğunu koruyor, bunlar arasında şunlar yer alıyor:
- 128k bağlam penceresi (DeepSeek’in API’si aracılığıyla 64k ile sınırlandırılmıştır)
- FP8 hassasiyeti için 700 GB’tan fazla GPU belleği gerektiren toplam 671 milyar parametre
- 37 milyar aktif parametre
- Yalnızca metin işlevselliği (çoklu biçimli destek yok)
- MIT Lisansı
700GB fazla hafıza ihtiyacı duyan model henüz evde çalıştırabileceğiniz seviyede değil 🙂