


Grafik işlemcilerinde hesaplama(GPU Computing) aslında çok yeni bir olgu değil. Grafik işlemcileri içerisine T&L;(Transform and Lightining) üniteleri girdiğinden beri bu konuda çalışmalar yapılıyor.
Peki ne oldu da bu kadar popüler bir konu oldu?
Bu günlerde iyice popüler olmasının başlıca iki nedeni var. Birincisi grafik işlemcilerinin ham matematiksel işlem gücü artık hiç olmadığı kadar yüksek, ikincisi ise grafik işlemcisi üreticileri artık bu gücü kullanmanız için size araçlar sunuyor ve hatta kullanmanız için sizi teşfik ediyorlar. Eskiden hem grafik işlemcileri çok daha güçsüzdü hemde bu grafik işlemcileri amaçlarınız doğrultusunda programlamak çok zordu. Dolayısı ile grafik işlemcisi üzerinden hesaplama yapan uygulamada pek yoktu.
Grafik işlemcisi ile hesaplama yapmanın felsefesini anlamak için aşağıdaki başlıkları okumaya devam etmelisiniz. Ancak şimdiden uyarmak gerekir ki, anlatım ne yazık ki biraz teknik olmak zorunda. Ancak elimizden geldiği kadar sadece ve anlaşılabilir anlatmaya çalışacağız.
Heterojen hesaplama nedir?
Heterojen programlama, en yüksek verimi alabilmek için uygulamaların uygulamanın tipine göre PC’nin ana iki işlemcisi olan CPU ve GPU’dan ayrı ayrı faydalanmaları gerektiği fikrini temel alır. CPU, birçok ayrıştırma ve rastgele bellek erişimi dolayısı ile seri işlemlerde en iyi sonucu verir. Diğer taraftan GPU ise kayar nokta (floating point) işlemleri ile paralel işlemlerde uzmandır. Kısacası en iyi sonuç seri işlemlerde CPU, paralel işlemlerde ise GPU kullanılarak elde edilebilir. Heterojen programlama, doğru işlem için doğru işlemciyi kullanmakla ilgilidir.
Seri ve Paralel Uygulamalar Nelerdir?
Çok nadir olarak uygulamalar sadece seri ve paraleldir. Çoğu uygulama belirli bir oranda her ikisine de ihtiyaç duyar. Derleyiciler, Kelime işlemciler, Web tarayıcıları ve e-posta istemcileri daha çok seri programlama gerektiren uygulamalara örnektir.
Video oynatma, video çözme, görüntü işleme, bilimsel hesaplamalar, fizik simülasyonları ve 3D grafikler (raytracing ve raster vb.) ise paralel işlemlerdir.
Not: Grafik işlemci ile hesaplamayı buradan sonra grafik işlemcisine hesaplama yaptırma yönünde epey yol alan ve rakibinden bir miktar önde olan NVIDIA üzerinden anlatacağız. Örnek grafik işlemcimizde NVIDIA’nın son grafik işlemcisi GTX280 olacak.
GeForce GTX280’i İdeal Paralel İşlemci Kılan Nedir?
Cuda:
Paralel programlamanın önündeki en büyük engel her zaman programlama zorluğu ve öğrenmek için kaynak yetersizliği olmuştur. Bu anlamda CUDA işleri inanılmaz ölçüde kolaylaştırmıştır. Sektörün ilk paralel programlama dili olan CUDA, piyasada bulunan 70 milyon CUDA destekli grafik işlemcisi ile aynı zamanda yüksek yayılma gücüne sahiptir. CUDA kolay ve güçlü olmasının yanı sıra görsel programlama uygulamalarında benzersiz ölçeklendirilebilirlik özelliğine de sahiptir. Örneğin CUDA, C/C++ programlama dili ile yazılmış uygulamalarınızı kolayca grafik işlemcinizin gücünden faydananmasına olanak sağlayacak şekilde yeniden derlemenize izin verebilir. (Ayrıntılara ileride değinilecek)

GPU Programlama Mimarisi:
GeForce GTX280 özellikle paralel programlama için tasarlanmış, paylaşımlı bellek ve çift kesinlik desteği gibi benzersiz özelliklerle donatılmıştır.
Çok Çekirdekli Mimari:
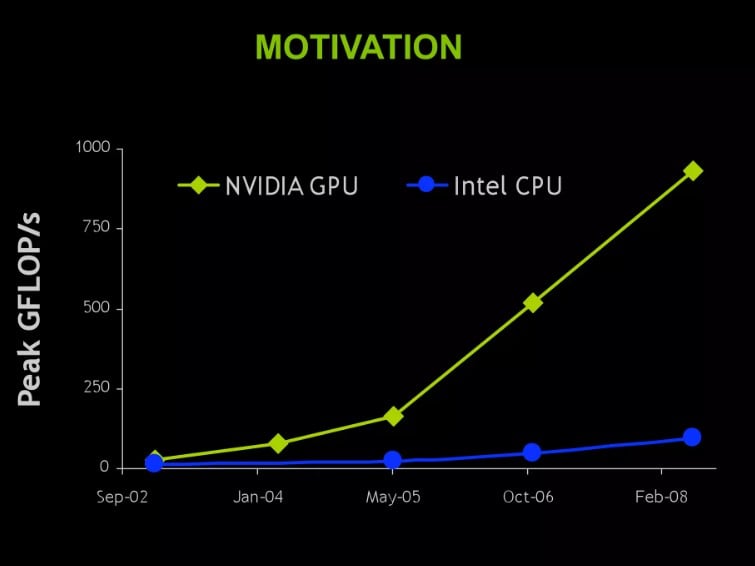
1.3 GHz hızında çalışan 240 çekirdek ile GeForce GTX280, PC için şimdiye kadar üretilen en güçlü kayar nokta işlemcisidir. Bu işlemci size yaklaşık 993GigaFLOP işlem gücü sunabilir.
Torrential Bantgenişliği: (kükremiş sel gibiyim bandımı ciğner taşarım)
8 adet bellek denetleyicisi ile GeForce GTX280, saniyede 141 GB veriye ulaşabilir ve bu da HD video çözme, fizik operasyonları ve görüntü işleme uygulamalarını çok büyük ölçüde hızlı yapmanıza izin verir.
NVIDIA CUDA Nedir?
CUDA, GPU üzerindeki yüzlerce(ilerde binlerce) çekirdeği kullanarak genel amaçlı matematik işlemleri yapmaya imkan sağlayan bir GPU mimarisi, yazılımı ve programlama platformudur. Programcılar C ve C++ programlama dillerine yapacakları bir ekleme sayesinde CUDA’yı edinebilir ve kullanabilirler.
CUDA CPU üzerinde de çalışır mı?
Evet. CUDA’nın yeni çıkacak versiyonu çok çekirdekli CPU’ları da destekliyor.
CUDA ve GPGPU arasındaki fark nedir?
GPGPU, DirectX ve OpenGL gibi API’ler kullanır. Grafik API’leri ve donanımı üzerinde ileri derecede programlama bilgisi gerektirir. Programlama modeli, rastgele okunan ve yazılan iş parçacıklarının birlikte çalışması üzerine kurulmuştur.
CUDA ise paralel programlama için C diline yapılan bir eklentidir. Programcının problemleri grafik konseptine dönüştürme mecburiyetini ortadan kaldırır. C üzerinde programlama yapabilen herkes CUDA’yı kolayca öğrenip kullanabilir.
Paralel Programlamanın zorlukları nelerdir? CUDA’da programlama ne kadar zor?
Paralel programlama, birden çok CPU’nun bir arada çalışmasını hedeflediği için zordur. Masaüstü uygulamalarının, (tek bir programı birden çok iş parçacığına dağıtılarak çalıştırılmak üzere hazırlanmasının zorluğundan dolayı) çok çekirdekli CPU’ların avantajlarını kullanmada yavaş kaldıkları bilinmektedir. Bu zorlukların sebebi, CPU’ların aslen seri işlemciler olmaları ve birden çok CPU’nun bir arada kullanılabilmesi için karmaşık yazılımlar gerekmesidir.
CUDA ise, manuel olarak paralellik yarattığı için bu zorlukları ortadan kaldırır. CUDA’da yazılmış bir program, aslında “kernel” adı verilen seri bir programdır. GPU bu kernel’in binlerce kopyasını çalıştırarak onu paralel hale getirir. CUDA, C dilinin bir uzantısı olduğu için genellikle programları CUDA’ya yönlendirmek veya onları multi-thread hale getirmek için mimarilerini değiştirmeye gerek yoktur. Bir döngüyü CUDA çağrısına dönüştürmek basit ve yeterlidir.
– CUDA’nın ana özellikleri nelerdir?
Paylaşılan bellek:
CUDA kullanabilen GPU’lardaki çoklu işlemcilerin her biri 16KB’lık bir paylaşılan belleğe sahiptir. Bu, farklı iş parçacıklarının birbirleri ile iletişim kurmalarına ve veri paylaşmalarına olanak verir. Paylaştırılmış bellek aynı zamanda yazılımsal olarak yönetilebilen tampon bellek olarak değerlendirilebilir, bu da ana belleğe ciddi miktarda bant genişliği kazandırarak önemli ölçüde hız artışı sağlar. Lineer cebir, hızlı Fourier dönüşümleri ve görüntü işleme filtreleri gibi yaygın uygulamalar bu özellikten faydalanabilirler.
Rastgele Yazma-Okuma (Toplama-dağıtma):
Grafik API’lerde parça programlar belirli bir bellek adresine 32 float (RGBA x 8 render hedefi) çıktı vermekle sınırlı iken, CUDA dağınık şekilde yazabilme (herhangi bir bellek adresine sınırsız sayıda yazma) özelliğine sahiptir. Bu, grafik API’lerini kullanılarak yapılamayacak yeni logaritmaların kullanılmasına olanak tanır.
Diziler ve Tamsayı Adreslemeleri
Grafik API’leri, kullanıcıyı verileri doku olarak depolamaya yöneltirler. Bu da uzun dizileri 2D dokular halinde gruplandırmayı mecbur kılar, dolayısı ile kullanışsızdır ve fazladan adresleme hesapları gerektirir. CUDA ise verilerin standart diziler halinde depolanmasına olanak verir ve herhangi bir adresten birçok işlemi yapabilir.
Dokulandırma Desteği:
CUDA, otomatik arabellek (cache), serbest filtreleme ve tamsayı adresleme özellikleri ile birlikte optimize edilmiş doku erişimi sağlar.
Bütünleştirilmiş Bellek Yığınları ve Depolanması:
CUDA, birden fazla bellek yığın isteğini ve yine birden fazla depolama isteğini birlikte gruplandırır, böylece bellekteki verileri parçalar halinde okuyup yazabilir. Bellek bant genişliğini maksimum düzeyde kullanır.
– CUDA programının yaratılma süreci ve GPU üzerinde çalıştırılması
İlk aşamada halihazırdaki uygulama veya logaritmanın bir profili çıkartılıp, hangi kısımlarının paralel çalıştırma için uygun olduğu ve diğer tarafta hangi kısımlarının darboğaza sebep olduğu belirlenir. Daha sonra bu işlevler CUDA’nın C eklentisine yönlendirilerek paralel veri yapıları ve işlemleri tanımlanır. Program, NVIDIA’nın CUDA derleyicisi kullanılarak hem CPU, hem de GPU için derlenir. Program çalıştırıldığında CPU kodun kendisine ait olan seri kısmını, GPU ise ağır hesaplamalar gerektiren paralel CUDA kodunu çalıştırır. Kodun GPU kısmına “kernel” adı verilir. Kernel, belirli bir veri kümesine uygulanacak olan işlemleri tanımlar.
GPU, veri kümesinin her unsuru için ayrı bir kernel kopyası yaratır. Bu kernel kopyalarına “iş parçacığı” (thread) adı verilir. Her iş parçacığı, kendine ait program sayacı, kayıt (register) ve durumu (state) barındırır. Görüntü veya veri işleme gibi geniş veri kümelerinde, bir seferde milyonlarca iş parçacığı yaratılabilir.
İş parçacıkları, “warp” (çözgü) adı verilen 32’li gruplar halinde yürütülürler. Warp’lar, çoklu akış işlemcilerine (streaming multiprocessor, SM) atanır ve buradan yürütülürler. Bir SM, sekiz çekirdekli bir işlemcidir. Her parçacık (veya saat döngüsü) başına bir yönerge çalıştırabilen her çekirdeğe akış işlemcisi (streaming processor,SP) veya parçacık işlemcisi adı verilir. Bu yüzden bir SM, her warp’ı yürütmek için 4 işlemci saatine ihtiyaç duyar. Yani bir akış çoklu-işlemcisinin, 32 iş parçacığını yürütmesi için 4 işlemci saati gerekir.
SM, geleneksel çok çekirdekli işlemci değildir. Bir seferde 32 warp’ı destekler ve yüksek miktarda çoklu iş parçacığını bir arada yürütebilir. Her saatte (döngüde) donanım hangi warp’ı (32’li iş parçacığı grubunu) çalıştıracağını belirler. Gecikmesiz olarak bir warp’tan diğerine geçiş yapar. CPU işlemlerine benzetilirse; 32 programı aynı anda çalıştırabilme, programlar arasında her saat döngüsünde gecikmesiz geçiş yapabilme özelliğine sahiptir. Pratikte çoğu CPU çekirdeği aynı anda birden fazla programa destek vermez, ancak programlar arasında yüzlerce saat döngüsü zamanda geçiş yapar.
Özetlemek gerekirse; yürütmenin üst seviyedeki akışı şu şekilde gerçekleşir:
Kernel’in tanımlanması, GPU’nun bu kernel’e göre iş parçacıklarını belirleyip çalıştırması, iş parçacıklarının warp adı verilen 32’lik gruplar halinde paketlenmesi ve bu warp’ların SM adı verilen yüksek multi-thread özellikli işlemciler tarafından yürütülmesi.
– CPU tarafında işlem modeli anlaşılabilir. Peki GPU işlemleri nasıl yapıyor?
Diyelim ki elimizde her biri 1000’er öğeden oluşan 2 adet dizi var ve bu öğelerin toplamını bulmak istiyoruz. CPU üzerinde çalışan program, iki dizide de her noktada tekrar tekrar toplamları alarak 1000 öğeli diziyi 1000 tekrarda tamamlar.
GPU üzerinde ise program 2 dizi üzerinde bir toplam işlemi olarak tanımlanır.
GPU programı çalıştırdığında, dizideki her öğe için toplama programının ayrı bir kopyasını oluşturur. 1000 öğeli bir dizi için 1000 adet “toplama işi parçacığı” yaratır. GeForce GTX280 üzerinde 240 adet çekirdek bulunur, yani her saat döngüsünde 240 iş parçacığı hesaplanabilir. Kısacası 1000 öğeli bir toplama işlemi GeForce GTX280 üzerinde 5 saat döngüsü zamanda tamamlanmış olur.
Burada önemli nokta, CUDA programının paralelliği tanımlayabilmesi ve GPU’nun da bu bilgiyi donanım üzerinde iş parçacıklarına dönüştürebilmesidir. Programcı böylece iş parçacıklarını yaratma, yönetme ve sonlandırma gibi işleri kendisi yapmak zorunda kalmaz. Aynı zamanda bir program bir kez derlendikten sonra değişik çekirdek sayısına sahip farkı GPU’lar üzerinde de çalıştırılabilir.
– GPU Mimarisi ve CPU Mimarisi arasındaki farklar
Bu konuya birçok farkı açıdan yaklaşılabiliriz:
Tasarım amacı:
Bir CPU çekirdeği, tek bir yönerge akışını bir kerede mümkün olduğu kadar çabuk yürütmek için tasarlanmıştır. GPU’lar ise birçok paralel yönerge akışını mümkün olduğu kadar çabuk yürütmek için tasarlanmışlardır.
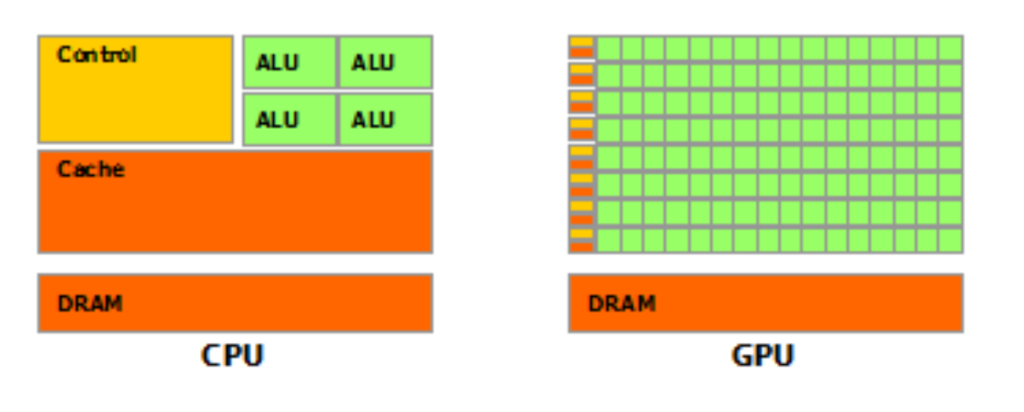
Transistör Kullanımı:
CPU’larda transistörler yönergelerin yeniden düzenlenmesini gerçekleştiren tamponlar, rezerve istasyonları, tahmin mekanizmaları ve büyük tampon bellek gibi bileşenlerden oluşur. Bu bileşenler, tek bir iş parçacığının yürütülmesini hızlandırmak için tasarlanmıştır. GPU’da ise transistorler işlemci dizileri, çoklu işlem donanımı, paylaşılan bellek ve birden fazla bellek denetleyicilere atanmıştır. Bu özellikler belirli bir iş parçacığının işletilmesinin hızlandırılmasına değil, yonganın üzerinde bulunan onbinlerce iş parçacığının aynı anda yürütülmesi için tasarlanmıştır ve böylece iş parçacıkları arasında iletişimi kolaylaştırarak yüksek bellek bant genişliği sağlar.
Arabelleğin (cache) Rolü:
CPU, biriktirme ara belleğini, genel bellek erişim gecikmesini azaltarak performans arttırmak amacıyla kullanır. GPU ise ara belleği (ya da yazılımla yönetilen paylaşılan belleği) bant genişliğini arttırmak için kullanır.
Gecikme (Latency) Yönetimi:
CPU’da bellek gecikmesi, geniş arabellekler ve tahmin mekanizmaları ile yönetilir. Bunlar tasarım üzerinde büyük yer kaplarlar ve genellikle güç tüketimi konusunda savrukturlar. GPU ise gecikmeyi binlerce iş parçacığını bir anda destekleyerek yönetir. Eğer herhangi bir iş parçacığı bellekten yük bekliyosa, GPU herhangi bir gecikmeye sebep olmadan derhal başka bir işe geçiş yapar.
Multi-threading:
CPU’lar, çekirdek başına bir veya iki iş parçacığı yürütme desteğine sahiptir. CUDA destekli GPU’lar ise akış işlemcisi başına 1024’e kadar iş parçacığı destekler. CPU’nun uygulamalar arasında bir kez geçiş yapması yüzlerce saat döngüsüne mal olurken, GPU’nun geçiş yaparken herhangi bir kaybı yoktur. Zaman kaybetmeden birçok gecişi ardı ardına yapabilir.
SIMD ve SIMT:
CPU’lar, vektörel işlemler için SIMD (Single Instruction Multiple Data – Tek Yönergeyle Birden çok veri) birimleri kullanırar. GPU’lar ise ölçekli yürütme için SIMT (Single Instruction Multiple Thread – Tek yönergeyle Birden çok İş Parçacığı) kullanırlar. SIMT, programcının verileri vektörler halinde düzenlemesini gerektirmez, iş parçacıkları için rastgele dağılıma olanak tanır.
Bellek Denetleyici:
Örneğin Intel CPU’lar üzerinde on-die bellek denetleyici bulunmaz.(ama yakında olacak) CUDA destekli GPU’lar, 8 adete kadar on-die bellek denetleyici kullanırlar. Sonuç olarak, GPU’lar, CPU’lara göre 10 kata kadar daha fazla bant genişliğine sahiptirler.
Teknik Özellikler:
Çekirdek Karşılaştırması(oransal):
GPU HESAPLAMA PERFORMANSI
Grafik işlemcileri gerçek dünyada neler yapabiliyorlar? GPU’lar, paralel uygulamalarda uzmandır. Uygun ortamlarda 10 ila 100 kat arası hız artışı gözlemlenebilir.
Video Dönüştürme:
GeForce GTX280 ile, 110 saniyelik bir video klip 21 saniye içinde kodlanabilir. Aynı klip en hızlı CPU ile 231 saniyede kodlanmaktadır.
BadaBoom Media Converter ile GPU destekli Video Encoding
Folding@Home
Folding@Home, Stanford Universitesi’nde geliştirilen ve bölüştürülmüş hesaplama yöntemi ile çalışan bir protein sarmalı katlama uygulamasıdır. Folding@Home GPU üzerinde, en hızlı CPU’dan 100 kat daha hızlı çalışmaktadır. Protein sarmalı hesapları, günde işlenen nanosaniye ile, (veya protein ömrünün kaç nanosaniyesinin bir günlük bilgisayar işlemi süresinde simule edilebileceğine dayanılarak) yapılır. GeForce GTX280 ile günde 590 nanosaniye seviyesine ulaşılabilirken, bir CPU ile bu oran günde 4 nanosaniye, Playstation 3 üzerinde ise 100 nanosaniyedir.
Sonuçlar aynı protein ve eşdeğer çalışma birimlerine dayanılarak bulunmuştur.
GPU’larda Fizik İşlemleri Performansı
Fizik simulasyonları da doğal olarak paralel işlemlerdir ve GPU üzerinde çok başarılı bir şekilde çalıştırılırlar. Aşağıdaki tabloda kumaş, yumuşak yüzeyler ve akışkan simulasyonları gibi sorunlu işlemlerin GPU ve CPU üzerinde nasıl işlendiği gösterilmiştir. GPU’nun ortalama performansı, PhysiX™ motoru eklenmiş ekran kartı destekli bir CPU’nun performansının 11 katı daha hızlıdır.